How to Decide Which Model to Use in Machine Learning
Size of the Training Data. If you have continues data then use linear regression.
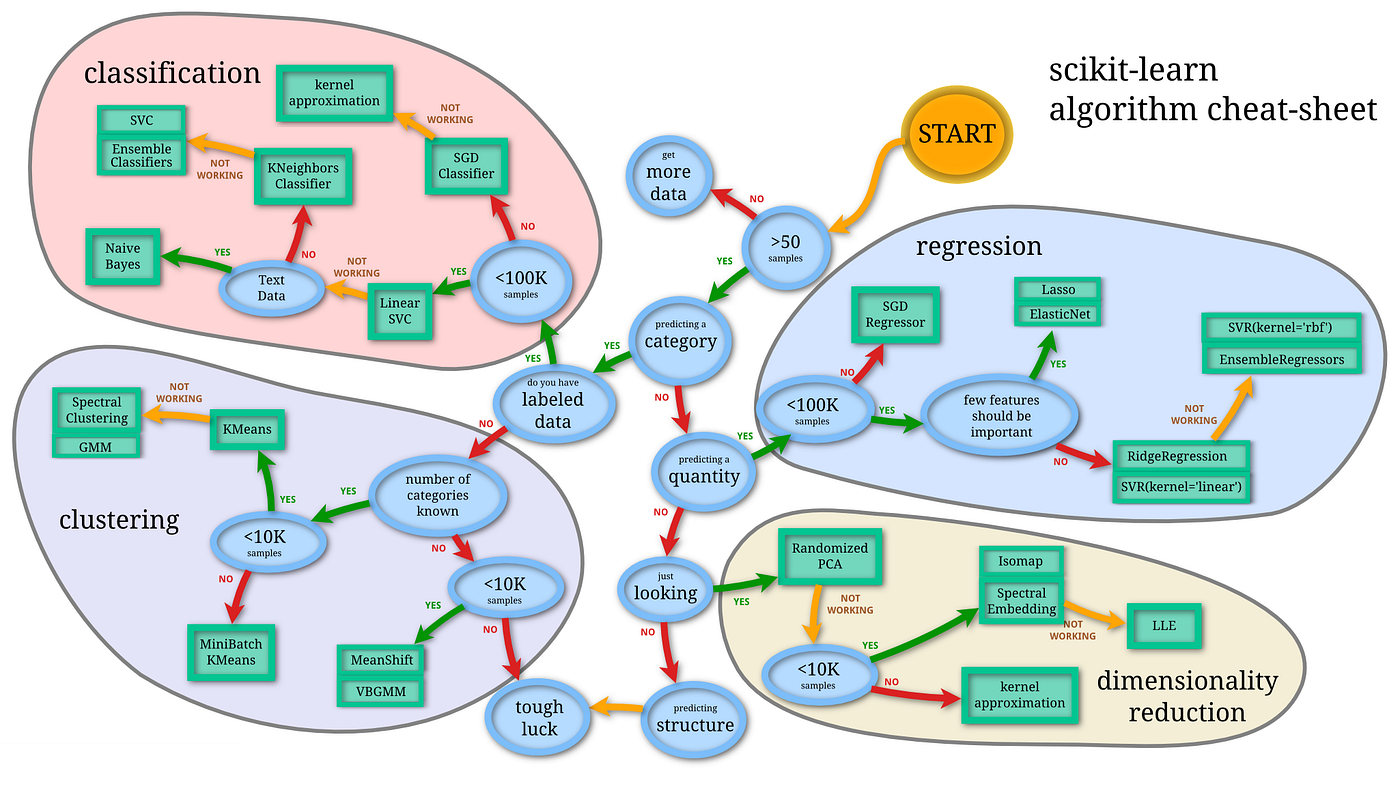
How To Choose Machine Learning Algorithms By Abolfazl Ravanshad Medium
There is a huge impact on the performance of the model by the feature selection.

. To train a model we first distribute the data into two parts. In this step you will check the accuracy of each of the machine learning algorithms. For example when training a model to predict future stock prices.
The next steps you can take are to start training models on a more complex dataset. A good model in data science is the model which can provide more accurate predictions. The answer depends on many factors like the problem statement and the kind of output you want type and size of the data the available computational time number of features and observations in the data to name a few.
However regression models or any model that tries to. A machine learning model will rank loan applicants into high-default-risk segments to low risk segments. For example we can check whether our natural language model picks up information about vocabulary names and arguments.
The proper way to pick a model. For example for the labeled dataset you will design all the models regression KNN decision trees and Naive Bayes. Slide 11 of this link shows the interpretability vs.
Here is another useful flowchart from SciKit Learn. In this post we explore some broad guidelines for selecting machine learning models The overall steps for Machine LearningDeep Learning are. Here is a really useful flowchart from Microsoft that presents different ways to help one to decide what algorithm to use when.
Hyperparameters play a significant role as they can directly control the behavior of the training algorithm. Set up a machine learning pipeline. In case you want to make topic modeling explanation below you use Singular Value Decomposition SVD or Latent Dirichlet Analysis LDA and use LDA in case of probabilistic topic modeling.
K-fold cross validation is the way to split our sample data into number the k of testing sets. In opposition to unsupervised learning supervised algorithms require labeled data. Topic modeling is a frequently used.
Machine learning ML related topics are a major trend. If you are having data with labels and features then everyone go with supervised learning models. Check for anomalies missing data and clean the data.
We just fit the features x and the target label y to the model by using the modelfit method provided by the scikit-learn library in Python. Model selection is a process that can be applied both across different types of models eg. Pick a diverse set of initial models.
There are several factors that can affect your decision to choose a machine learning algorithm. The goal is to select the best possible set of features for the development of a machine learning model. So a good first step is to quickly test out a few different classes of models to know which ones capture the underlying structure of your dataset most efficiently.
Here are some important considerations while choosing an algorithm. Along with data cleaning feature selection should be the first step in a model design. Perform statistical analysis and initial visualization.
Countless blog posts exist covering how to create various models juggle them around use IT applications etc. Figure 1 illustrates the point. 24 of the applicants in Segment 1 or 2400 2410000.
If we choose them effectively it will eventually lead to the better performance of our machine learning model. This is arguably the largest and most popular group of machine learning algorithms. So this is how you can easily train machine learning models.
Based upon the data is continues or discrete you can select whether to use regression model or classification model. It will compare the performance of each algorithm on the dataset based on your evaluation criteria. You will choose the model that has a high level of accuracy.
Topic modeling is a type of statistical model for discovering the abstract topics that occur in a collection of documents. A more behavioral way to organize machine learning tests is to focus on the skills we expect from the model as suggested by this paper about testing NLP models. Logistic regression SVM KNN etc and across models of the same type configured with different model.
Provide a dataset that is labeled and has data compatible with the algorithm. Another approach is to divide your data into subsets and use the same algorithm on different groups. Supervised learning is flexible comprehensive and covers a lot of the common ML tasks that are in high demand today.
In x we store the most important features that will help us predict target labels. Choosing suitable hyperparameters plays a crucial role in the success of our neural network architecture. Just as physicists believe that ultimately all of their field can be reduced down to the study of one force there are possibly many in machine learning who believe that ultimately human or machine learning is best modeled as solving one overarching learning problem and all others are derived.
However these articles rarely address the prerequisites for making them production worthy or even possible. In Machine Learning designer creating and using a machine learning model is typically a three-step process. In this case you can test a couple of models and assess them.
In y we only store the column that represents the values we want to predict. Before predicting values using a machine learning model we train it first. Configure a model by choosing a particular type of algorithm and then defining its parameters or hyperparameters.
How to determine the value and efficacy of machine learning. Present the results Machine learning tasks can be. First a bit more precision is necessary.
In order to find a accurate model the most popular technique is using k-fold cross validation. How to pick a machine learning model 1. Accuracy tradeoffs for the different machine learning models.
In the same way you can do for the unlabeled dataset. Model selection is the process of selecting one final machine learning model from among a collection of candidate machine learning models for a training dataset. Supervised machine learning algorithms.
Different classes of models are good at modeling different kinds of underlying patterns in data. Supervised learning have two major class of problems.

Supervised Learning In Business Common Use Cases Supervised Learning Machine Learning Machine Learning Deep Learning

Choosing The Right Metric For Evaluating Machine Learning Models Part 1 Machine Learning Models Machine Learning Machine Learning Examples
How To Choose An Evaluation Metric For Imbalanced Classifiers Class Labels Machine Learning Metric

Comments
Post a Comment